告别繁琐日志捞取 这款可视化开源监控系统,重塑运维效率
在当今数字化浪潮中,信息系统运行维护服务面临着前所未有的挑战。服务器日志,作为系统运行的“黑匣子”,蕴含着性能瓶颈、安全威胁与故障根源的关键信息。传统的日志捞取方式——通过命令行逐台登录服务器、在浩如烟海的文本文件中筛选关键词——不仅耗时费力,更在问题定位上存在严重滞后,往往让运维团队疲于奔命,陷入“救火队员”的被动角色。
正是在这样的背景下,一款优秀的可视化开源监控系统应运而生,它正彻底改变着运维工作的范式,让运维人员得以从繁琐重复的劳动中解放出来,将精力聚焦于更具价值的分析与优化工作。
核心痛点:传统日志管理的桎梏
传统运维模式下,日志管理存在几大痛点:
- 分散与割裂:日志分散在各台服务器、不同应用与容器中,缺乏统一视角。
- 非实时性:问题发生后,才被动地去追溯日志,错过了最佳干预时机。
- 可读性差:原始日志晦涩难懂,需要专业知识和大量时间进行解析。
- 效率低下:手动操作极易出错,且无法进行大规模、跨时间维度的关联分析。
破局利器:可视化开源监控系统的核心价值
现代的可视化开源监控系统(如Prometheus + Grafana的组合、Elastic Stack等明星方案)通过以下方式,为运维服务带来了革命性提升:
1. 统一采集与集中管理
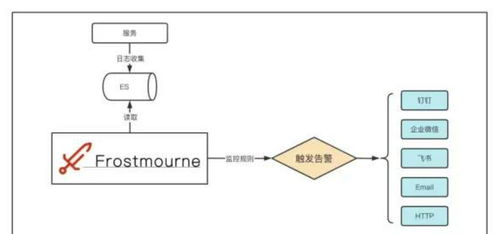
系统通过轻量级的代理(Agent)或标准接口,自动从各个服务器、容器、中间件和应用中采集指标数据与日志流。所有数据汇聚到中心存储,形成一个统一的“运维数据湖”,打破了数据孤岛。
2. 实时监控与智能预警
系统对采集到的性能指标(如CPU、内存、磁盘IO、网络流量)和日志事件进行实时处理与计算。通过预设的阈值或基于机器学习的异常检测模型,系统能在问题萌芽阶段(如响应时间变慢、错误率上升)自动触发预警,通过邮件、钉钉、微信等渠道通知相关人员,变被动为主动。
3. 强大直观的可视化展现
这是其得名的关键。系统提供丰富的仪表盘(Dashboard)功能,运维人员可以通过拖拽方式,将核心指标以折线图、热力图、拓扑图、地理分布图等多种形式直观展现。整个系统的健康状态、性能趋势、业务流量一目了然。更重要的是,可以直接在图表上对异常点进行下钻(Drill-down),快速关联查看到对应的原始日志明细,实现了从宏观态势到微观根因的无缝追溯。
4. 强大的搜索与分析能力
集成高效的搜索引擎,支持对海量日志进行全文检索、模糊查询和字段过滤。结合强大的查询语言,可以轻松完成诸如“统计过去一小时来自特定IP的404错误数量”、“找出所有包含‘Timeout’异常且响应时间大于2秒的请求”等复杂查询,效率相比手工grep命令呈指数级提升。
5. 开源生态与成本优势
作为开源软件,它们避免了商业软件高昂的许可费用。活跃的开源社区提供了丰富的插件、集成方案和最佳实践,能够灵活适配各种技术栈(Kubernetes, Docker, MySQL, Nginx等)和业务场景。企业可以根据自身需求进行定制化开发,掌控核心技术。
实践场景:运维效率的飞跃
- 故障排查:当收到业务接口超时告警,运维人员无需登录服务器。只需在监控仪表盘上点击异常时间点的图表,直接链接到相关应用的错误日志,快速定位是数据库连接池耗尽,还是某个下游服务异常,将平均故障恢复时间(MTTR)大幅缩短。
- 容量规划:通过长期趋势图,清晰预测业务增长带来的资源压力,为服务器扩容或优化提供数据支撑。
- 安全审计:实时监控异常登录行为、敏感操作日志,并进行可视化呈现,助力安全合规。
- 性能优化:分析各服务调用链路的耗时分布,直观找出性能瓶颈所在。
****
引入一款功能强大的可视化开源监控系统,对于信息系统运行维护服务而言,已非锦上添花,而是提升效能、保障稳定、驱动创新的必然选择。它让运维团队告别了在命令行海洋中“捞针”的窘境,转变为坐在“驾驶舱”内,通过全景式仪表盘掌控全局的指挥官。这不仅提升了系统的可靠性与安全性,更将运维工作从成本中心推向价值创造的前沿,为业务的持续稳定发展奠定了坚实的基石。拥抱这样的工具,就是拥抱高效、智能的运维未来。
如若转载,请注明出处:http://www.qhdmember.com/product/60.html
更新时间:2026-06-19 20:07:32